Weird Data Champion and Google Search
Checking my web analytics, I noticed that Design & Analytics is now in the coveted #4 google hit position for "weird data sets." That means I'm probably pretty close to getting Nike sponsorship and my face on a Wheaties box in the data olympics category.
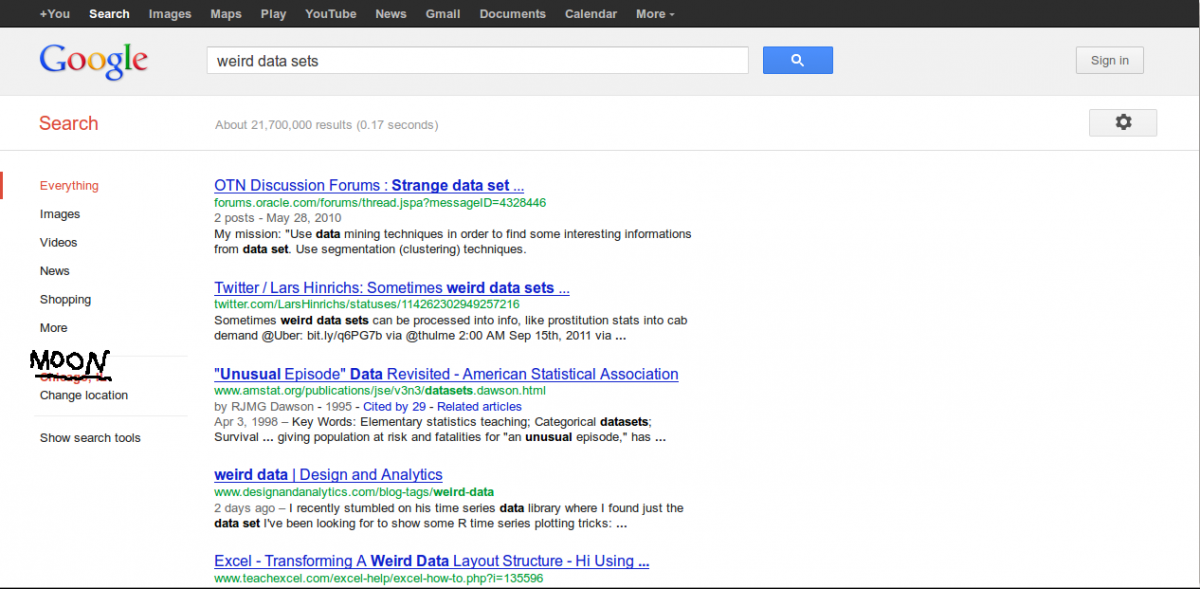
At first glance, this is mostly from the two articles I've posted doing time series analysis in R on the quirky beard fullness data set. But I suspect a second part of it is related to the rollout of google's new search algorithm, Penguin, released just a couple days ago. This is because when I search for "weird data sets" not only do I see hits for "weird data" but also for "strange data." The algorithm knows they're synonyms, which makes sense, but is a new feature, as far as I know. I don't know whether this was always the case, but I tested a couple of alternatives where "weird" and "strange" might actually be different in meaning...
First thing that comes to mind is searching for "The weird sisters" a la MacBeth---"weird" has a particular meaning here different from "strange" in identifying this. Sure enough, none of the top hits replace 'weird" with "strange"---even as deep as results page 22 where I stopped looking. Although this is likely because of result density rather than intent (this is a huge book?). Maybe on page 100, it throws in an alternative. However, I think the upgrade actually has distinguished usages when "weird" is different from "strange" in changing the meaning of the query.
That is, you're probably equally likely to search for "weird data sets" and "strange data sets" and want the same result---but when you search for "weird sisters" you don't want the "strange sisters" (especially if you're at work, because it might get blocked in an overzealous firewall...)
To me this suggests that google is doing bona fide Natural Language Processing here---examining your query for what you mean by the semantics of the words, not just what the words are, and their statistical relationships to each other. I had talked with a friend doing NLP research recently and heard that google was alarmingly far behind in this field, favoring mostly statistical relationships, so this was a pleasant (and well, as everything with google, slightly terrifying) surprise.